Le questionnaire AttrakDiff, élaboré par Hassenzahl et ses collègues en 2003, est un outil de référence pour les chercheurs en UX. Il permet d’évaluer les qualités hédoniques et pragmatiques des systèmes interactifs. Jusqu’en 2014, il n’avait jamais été traduit et validé en version française. Afin de pouvoir étudier l’UX sur des échantillons francophones dans le cadre de ma thèse, j’ai traduit et validé ce questionnaire en suivant une méthodologie scientifique (ce qui permet de garantir les qualités psychométriques de l’outil traduit).
Le modèle théorique d’Hassenzahl
AttrakDiff est basé sur un modèle théorique développé par le chercheur Marc Hassenzahl et son équipe. Selon ce modèle, les utilisateurs perçoivent les produits interactifs selon deux dimensions :
- les qualités pragmatiques : capacité à soutenir l’accomplissement de “do-goals” (tâches). Focus sur le produit (utilité, utilisabilité, réalisation des tâches). Un produit perçu comme ayant de bonnes qualités pragmatiques sera structuré, clair, contrôlable, efficace, pratique, etc.
- les qualités hédoniques : capacité à soutenir l’accomplissement de “be-goals”. Focus sur le soi (pourquoi on possède et on utilise un produit particulier). Un produit perçu comme ayant de bonnes qualités hédoniques sera original, créatif, captivant (versant hédonique – stimulation) ou encore présentable, professionnel, de bon goût, qui me rapproche des autres (versant hédonique – identification).
Ces deux dimensions (pragmatique et hédonique) vont influencer la perception subjective de l’attractivité du produit ou système, qui va donner naissance à des comportements (par exemple une utilisation accrue) et émotions (ex : joie, frustration).

L’AttrakDiff, un outil de mesure quantitative de l’expérience utilisateur
L’AttrakDiff est un questionnaire standardisé comprenant 4 sous-échelles de 7 items chacune, soit 28 items au total. Il est exploité par la société allemande User Interface Design GmbH, qui propose la passation en ligne gratuitement (en allemand et en anglais) sur son site http://attrakdiff.de/
Les sous-échelles de l’AttrakDiff sont les suivantes :
- Echelle de qualité pragmatique (QP) : décrit l’utilisabilité du produit et indique à quel point le produit permet aux utilisateurs d’atteindre leur(s) but(s)
- Echelle de qualité hédonique – stimulation (QH-S) : indique dans quelle mesure le produit peut soutenir le besoin de stimulation
- Echelle de qualité hédonique – identification (QH-I) : indique dans quelle mesure le produit permet à l’utilisateur de s’identifier à lui
- Echelle d’attractivité globale (ATT) : décrit la valeur globale du produit basée sur la perception des qualités pragmatiques et hédoniques
Format : Les items se présentent sous la forme de différenciateurs sémantiques (paires de mots contrastés) à évaluer par des échelles de Likert en 7 points. L’ordre de passation des items est standardisé. Ceux-ci sont mélangés et les 7 items d’une même sous-échelle ne sont jamais passés à la suite.
Passation et scoring
Passation : L’AttrakDiff est un outil auto-administré. Les utilisateurs peuvent y répondre aussi bien en présentiel (après un test utilisateur par exemple) qu’en ligne. La passation dure généralement entre 5 et 10 minutes maximum. Pour les plus pressés, une version raccourcie existe en 10 items seulement.
Types d’évaluation : L’AttrakDiff soutient 3 types d’évaluation
- Evaluation unique : adaptée pour une évaluation unique ou temporaire d’un produit ou système
- Comparaison avant-après : ce type d’évaluation permet de tester le produit 2x : avant et après l’implémentation de changements. Vous aurez ainsi un résumé détaillé des effets des changements.
- Comparaison Produit A – Produit B : ce type d’évaluation implique deux produits qui sont évalués et comparés. Vous serez en mesure de voir comment les utilisateurs perçoivent les différents produits.
Scoring : Le scoring de l’AttrakDiff est relativement facile.
- Tout d’abord, il faut inverser certains items, c’est à dire transformer le score obtenu par son opposé (+3 depuis -3, +2 devient -2, etc). Cette étape est nécessaire car, pour éviter la tendance à l’acquiescement lors de la passation, les items n’ont pas la même valence (parfois le mot à gauche est négatif et parfois il est positif). Avant de calculer un score, il faut donc s’assurer que les items sont bien scorés dans le même sens, c’est à dire que les termes négatifs soient à gauche et les termes positifs à droite.
![]()
- Il s’agit ensuite de calculer les moyennes et écart-types pour chaque échelle, ainsi que les intervalles de confiance (le calcul de l’intervalle de confiance est détaillé dans les slides de l’atelier Evaluation UX)
Présentation des résultats
La présentation des résultats peut se faire sous différentes formes. Les concepteurs de l’outil en proposent 3 formes principales.
Diagramme des valeurs moyennes
 Les valeurs moyennes des différentes dimensions de l’AttrakDiff sont représentées sur ce diagramme. Les qualités hédoniques stimulation et hédoniques identité sont distinguées et l’attractivité globale est présentée.
Les valeurs moyennes des différentes dimensions de l’AttrakDiff sont représentées sur ce diagramme. Les qualités hédoniques stimulation et hédoniques identité sont distinguées et l’attractivité globale est présentée.
Les valeurs proches de la moyenne (zone entre 0 et 1) sont standards. Elles ne sont pas négatives et remplissent leur fonction. Toutefois, des améliorations sont possibles sur ces aspects pour créer une UX ou attractivité très positive.
Graphique des paires de mots
Ce diagramme présente les valeurs moyennes pour chaque paire de mots. Les items sont regroupés par sous-échelles et placés autour d’un continuum avec au centre la valeur neutre 0, ce qui permet de distinguer très rapidement quels aspects sont perçus comme négatifs et quels aspects sont perçus comme positifs.
Les valeurs extrêmes (entre -2 et -3 ou à l’inverse entre +2 et +3) sont particulièrement intéressantes. Elles montrent quelles dimensions sont critiques ou au contraire particulièrement positives, et appellent à des actions d’amélioration sur ces aspects.
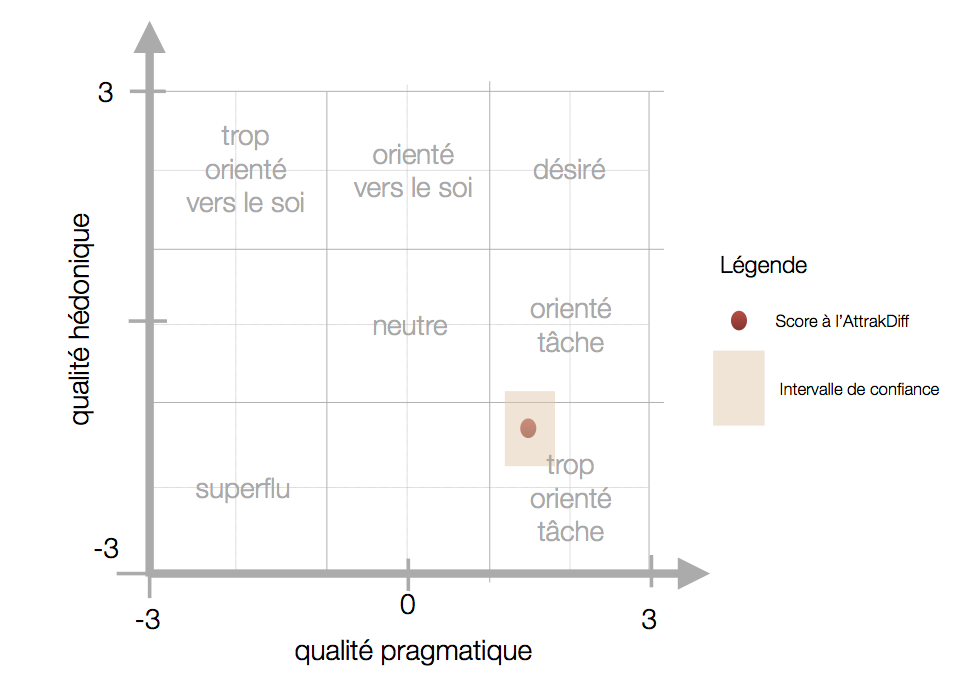
Portfolio des résultats
Dans cette représentation des résultats, les valeurs moyennes obtenues aux échelles hédoniques sont représentées sur l’axe vertical (avec en bas valeur la plus basse, soit -3) et la valeur moyenne à l’échelle pragmatique est représentée sur l’axe horizontal (à gauche valeur la plus basse). Selon les scores obtenus aux deux dimensions, le produit ou système évalué sera positionné dans l’une des zones, définissant ainsi sa « personnalité » ou son « orientation ».
Chaque valeur moyenne est entourée d’un rectangle représentant l’intervalle de confiance du résultat. Le rectangle de confiance montre si les utilisateurs ont fait une évaluation homogène du produit ou si on constate une grande variété dans l’évaluation. Plus l’intervalle de confiance est grand, plus l’évaluation a varié selon les utilisateurs. Ainsi, il est plus difficile de catégoriser le produit dans une zone particulière. Un petit intervalle de confiance est un avantage car il signifie que les résultats sont plus précis et plus fiables.
Conseils pratiques
- L’AttrakDiff étant un outil quantitatif, essayez d’avoir un échantillon d’utilisateurs raisonnable pour une passation.
- Ne modifiez aucun élément de l’AttrakDiff (formulation des items, nombre d’items, format, ordre de passation, etc) sous peine de détériorer les qualités psychométriques du questionnaire.
- Utilisez la version courte (abridged AttrakDiff) en 10 items si vous ne pouvez pas faire passer l’échelle complète.
- Ajoutez avant ou après l’AttrakDiff des questions socio-démographiques pour croiser les résultats en fonction de certaines caractéristiques de votre échantillon. Les plus fréquentes sont le sexe, l’âge et le sentiment de maîtrise des technologies.
Retrouvez les items de la version française ainsi que les instructions de passation dans la section Ressources.
La version abrégée du questionnaire consiste en une sélection de dix items sur les 28 que comprend l’outil d’origine Voilà les codes des items à retenir pour la version courte :
• qualité pragmatique (4 items) : QP2, QP3, QP5, QP6 ;
• qualité hédonique (4 items) : QHS5, QHS2, QHI3, QHI4 ;
• attractivité (2 items) : ATT2, ATT5.
Sources
- Création de l’outil : Hassenzahl, M., Burmester, M., Koller, F. (2003) AttrakDiff: Ein Fragebogen zur Messung wahrgenommener hedonischer und pragmatischer Qualität. In: Ziegler, J., Szwillus, G. (eds.) Mensch & Computer 2003. Interaktion in Bewegung, pp. 187–196. B.G. Teubner, Stuttgart.
- Site web : http://www.attrakdiff.de.
- Traduction française : Lallemand, C., Koenig, V., Gronier, G., & Martin, R. (2015). Création et validation d’une version française du questionnaire AttrakDiff pour l’évaluation de l’expérience utilisateur des systèmes interactifs. Revue européenne de psychologie appliquée, 65(5), p 239-252.

voilà une bonne chose, j’avais utilisé ce questionnaire dans le cadre de mon stage de fin d’étude l’année dernière mais je n’avais trouvé aucune version traduite, du coup j’avais traduit moi-même donc bon, niveau fiabilité, pas sûr… Je le trouve très intéressant comme outil car il reprend plusieurs aspects de l’UX dans un même questionnaire contrairement à d’autres outils qui ne traite que de l’émotion etc….et il est assez rapide à faire passer dans un contexte d’entreprise. Je suis contente que vous l’ayez traduite pour de futures évaluations d’interfaces!
Bonne continuation dans vos recherches…
Bonjour;
Je suis un étudiant en M2 recherche marketing a l’institut des hautes études de Carthage;
Dans le cadre de mon mémoire d’étude qui se porte sur l’effet de l’expérience d’utilisation des tables interactives sur la valeur perçu de l’expérience de consommation dans le milieu de la restauration, j’aurais fortement besoin de la version française du questionnaire AttrakDiff de Hassenzahl traduit et validé par Docteure Carine Lallemand pour pouvoir avancer dans mes recherche, Veuillez m’indiquer dans quelle publication ou ouvrage je peux le trouver.
En attendant votre réponse veuillez agréer mes salutations distinguées.
OUICHNI MEDALI
ouichni.medali@gmail.com
Bonjour Carine,
Pour faire suite au commentaire ci-dessus, distribuez-vous la traduction française du questionnaire AttrakDiff ?
Merci d’avance
Bonjour Charles,
Je viens d’ajouter les consignes et items de la version française en pdf à la fin de l’article.
Merci pour votre intérêt !
Bonjour Carine, avez-vous eu le temps de mettre en ligne la version française ? Merci !
Bonjour Charles, oui à l’instant même sur Slideshare et sur le blog. Désolé pour le délai !
Bonjour,
je trouve ce modèle très intéressant parce qu’il prend en compte le point de vue du concepteur et de l’utilisateur tout en restant compact. Est-ce que vous avez des études comparatives de ce modèle avec d’autres types d’évaluation comme le System Usability Scale (SUS) par exemple ?
Merci pour votre commentaire ! Concernant le SUS, il faut savoir que c’est une échelle d’utilisabilité et non d’UX, c’est-à-dire qu’une évaluation avec le SUS ne peut pas être comparée avec l’ensemble de l’échelle AttrakDiff, cela n’aurait pas de sens car on n’évalue pas la même chose.
En revanche on peut comparer un score au SUS avec la sous-échelle AttrakDiff des qualités pragmatiques (donc les 7 items QP uniquement). Se faisant, on obtiendrait une évaluation de la validité convergente de cette sous-échelle ; cette forme de validité désigne le fait que deux outils sensés mesurer la même chose sont effectivement corrélés entre eux.
Merci pour la réponse Carine. Oui j’ai vu la différence UX vs Usability. Faut-il mieux utiliser 7 items pour le SUS afin de s’aligner sur les 7 items de la qualité pragmatique (QP) pour avoir une échelle équivalente ? Je me demandais si on pouvait aussi comparer le Single Ease Question (SEQ) à 7 items avec le QP même si le SEQ risque d’être déjà plus spécifique.
La Comparaison Produit A – Produit B par Attrakdiff pourrait être mis à profit pour compléter un test de Kano. Ce serait pas mal d’avoir un exemple. Je vais fouiller un peu les articles d’Hassenzahl, le site et voir l’UEQ.
En réalité quand on teste la validité convergente, le nombre d’items de chaque outil importe peu et il n’est pas nécessaire d’avoir 7 items vs 7 items ici. De même il n’est pas nécessaire que les échelles aient le même format (on peut très bien corrélé des échelles de Likert en 7 points avec des échelles de Likert en 5 points). Du coup ma question : que cherches tu à travers ces éventuelles comparaisons ?
Pour la combinaison AttrakDiff – Kano cela semble une très bonne idée ! Car ce que l’Attrakdiff ne dit pas vraiment (même si on peut le calculer avec un modèle de régression – mais disons que les pros ne vont pas faire cela) c’est l’importance pondérée des aspects pragmatiques ou hédoniques dans l’évaluation de l’attractivité globale. Le modèle postule que les deux dimensions sont importantes, bien entendu, mais selon le contexte et le type de système l’une peut prendre un peu le pas sur l’autre.
Hassenzahl n’a en réalité jamais présenté d’étude de validation statistique complète de l’Attrakdiff. L’article de 2003, en allemand, où il présente l’outil et décrit ses qualités psychométriques est largement insuffisant dans son argumentation et ses métriques (par exemple taille d’échantillon bien trop petite). En revanche d’autres ont étudié un peu plus en profondeur l’Attrakdiff anglais et ont montré que le modèle est valide malgré la faiblesse de certains items, tout comme je l’ai fait pour la version française. Si tu es curieux et souhaites en savoir plus sur la démarche de validation d’AttrakDiff et le background théorique derrière sa construction, je peux t’envoyer mon article sur le sujet (scientifique mais en français ^^). Tu peux le trouver sur le net mais payant, envoie moi ton adresse mail en privé si tu veux.
Pour l’UEQ tu verras que le site propose une version française… Traduite via Google traduction. A fuir ! Idem pour la version anglaise qui n’est pas valide malheureusement et ne correspond pas à la version originale allemande (or seule cette dernière a fait l’objet d’une validation statistique).
Bonjour,
Merci pour cet article.
Il me semble qu’il est évoqué ici différents types de validation.
Dans votre article “Création et validation d’une version française du questionnaire AttrakDiff pour l’évaluation de l’expérience utilisateur des systèmes interactifs”, ne s’agit-il pas uniquement d’une validation psychométrique par rapport à la version originale (donc une validation de traduction) ?.
Je ne vois pas de validation psychométrique de la mesure elle-même (censée mesurer ce qu’elle doit mesurer).
Auriez-vous plus d’informations sur le sujet, y compris pour les validations de la version anglaise que vous évoquez ?
Cordialement
Bonjour Carinne,
Tu parles de l’attrakDiff mini (en 10 items), sera-t-il possible de connaitre ces 10 items en français?
Bonjour Marie,
Oui, le questionnaire AttrakDiff comprend effectivement une version abrégée et c’est en fait une sélection des dix items les plus représentatifs de l’outil. Voilà les codes des items de la version courte :
• qualité pragmatique (4 items) : QP2, QP3, QP5, QP6 ;
• qualité hédonique (4 items) : QHS5, QHS2, QHI3, QHI4 ;
• attractivité (2 items) : ATT2, ATT5.
Merci pour ta question, je vais ajouter ça à l’article de ce pas.
Bonjour Carine, on s’est croisée à BlendWebMix et ça m’a donné envie d’essayer d’utiliser plus d’outils issus de la recherche, dont notamment l’AttrakDiff. Plusieurs questions :
1. Qu’est ce que tu penses d’utiliser ce test avec un délai de quelques jours, pour évaluer davantage le souvenir de l’expérience ? C’est ce que j’ai fait pour tester l’outil car j’avais une personne sous la main qui avait testé ma webapp il y a 5 jours, et je trouve ça assez pertinent par rapport à tout ce que tu as raconté à Lyon sur l’importance du souvenir.
2. Je fais des tests utilisateurs de manière assez sporadique, dans le cadre d’une organisation agile où on ajoute des fonctionnalités très régulièrement sur un projet encore en R&D, donc plus en mode “test – corrige – test – corrige”. Est-ce que ça a du sens d’utiliser l’attrakDiff dans un tel contexte, où l’interface va forcément changer à travers mon échantillon ?
Merci encore dans tous les cas pour toutes ces chouettes ressources !
Bonjour Karine,
Je me demandais s’il était intéressant de faire aussi passer ce formulaire aux employés d’un service pour permettre de comparer les résultats avec ceux des utilisateurs. Et donc ainsi révéler des biais de perception entre eux ?
Bonjour Karine,
Je me demandais s’il était intéressant de faire passer ce formulaire aux employés d’un service pour permettre de comparer les résultats avec ceux des utilisateurs. Et donc ainsi révéler des biais de perception entre eux ?
Merci.
Bonne journée !